
原子操作是比互斥锁还要low-level的同步模型,我第一次听到原子操作这个概念,是在操作系统课上,即互斥锁的加锁和解锁是原子操作。其实加锁、解锁就是在维护一个flag,该flag是原子类型,++、–要么不执行,要么一口气执行。
以最简单的i++为例,cpu在执行时不是一步到位的,而是被编译成三步:load、add、store。在单线程中不成问题,但到多线程中就会出现数据丢失的情况:
| thread A | thread B |
|---|---|
| load i | |
| load i | |
| add i | |
| store i | |
| add i | |
| store i |
最后i的结果为1,为此不可打断的原子操作很重要。
下面先来讲一下原子操作的底层实现。
原子操作在CPU中的实现
首先,明白一点,由于总线等资源的独占性,一次读或者一次写,是”天然“atomic的。
因为总线上只能传输一份数据,在电路级别上就是不可分割的。当然提前是数据小于总线宽度、且与cache行地址对齐。否则读or写一份数据要多次。
当不满足上述条件时,CPU通过锁总线和锁cache来实现其他原子操作:
锁总线
锁住总线,避免在此指令执行期间其它核心/其它CPU对内存进行操作。但是这种方法缺点很明显,一棒子全打死效率较低。
锁cache
除了I/O,大部分的内存可以被cache命中,那么我们只要以cache行为单位进行互斥访问(相当于给cache上锁),不就行了。
所以比较近代的CPU利用缓存一致性协议,对此进行了改进,只是将相应的cache行声明为独占进行锁定。
思考一个问题:如果操作的数据跨越了2个cache块,此时锁cache还能用吗?不行了,这时老老实实采用锁总线。
更详细介绍,请参考[文章](https://zhuanlan.zhihu.com/读写一气呵成 – Linux中的原子操作 – 兰新宇的文章 – 知乎 https://zhuanlan.zhihu.com/p/89299392)。
其实原子操作的概念是广义的,在单核cpu中,关中断也可以看成广义上的原子性。
CAS
CAS全称是Compare And Set,是常用的一条CPU原子指令。下面内容参考该[视频](https://zhuanlan.zhihu.com/(10min理解)锁、原子操作和CAS – 知乎 https://www.zhihu.com/zvideo/1356595449852559360)。
CAS用途非常广泛,一个主要用途是用CAS来实现自旋锁。
bool compare_and_swap(&old_value,expect,new_value);CAS的执行结果是:
- 如果old_value==expect,那么把old_value更新为new_value;
- 反之,什么也不做;
CAS代表:one thread fail means one thread success.
比如下面这个例子,i初始0,两个线程都想把i从0更新到1。
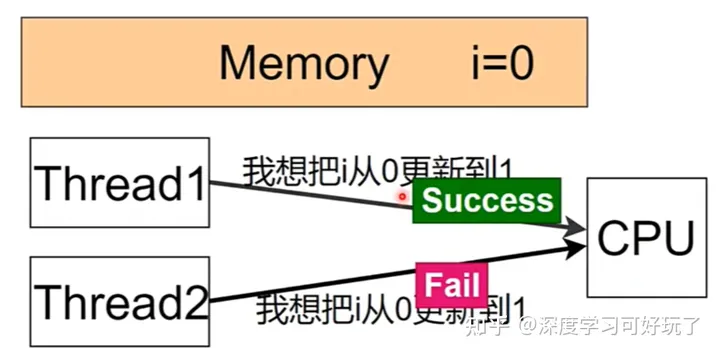
thread1: cas(&i,0,1);
thread2: cas(&i,0,1);如果有一个线程失败,必定是另一个线程成功更改了i值。
下面用CAS来实现自旋锁
class Spinlock{
int i=0;
void lock(){
while(!cas(&i,0,1)); // 相当于i++
}
void release(){
while(!cas(&i,1,0)); // 相当于i--
}
};在多线程编程中CAS用于lock-free,在数据库中,CAS又用于乐观锁。本质都是一个意思。
C++原子类型
C++作为系统编程语言,在现代C++中提供了原子类型和内存顺序,让程序员实现low-level的并发编程。
C++11标准在标准库<atomic>头文件提供了模版atomic<>来定义原子类型:
template< class T >
struct atomic;它提供了一系列的成员函数用于实现对变量的原子操作,例如:
- 读操作load;
- 写操作store;
- compare_exchange_weak/compare_exchange_strong(就是CAS操作)等。
注意:CAS操作在float、double下使用需要小心,因为CAS是按位比,而浮点数的尽管真值相同,但物理存放的位比特可能不同。不过想必也很少用atomic_float。
此外,对于大部分内建类型,C++11提供了一些特化,参考文章:
std::atomic_bool std::atomic<bool>
std::atomic_char std::atomic<char>
std::atomic_schar std::atomic<signed char>
std::atomic_uchar std::atomic<unsigned char>
std::atomic_short std::atomic<short>
std::atomic_ushort std::atomic<unsigned short>
std::atomic_int std::atomic<int>
std::atomic_uint std::atomic<unsigned int>
std::atomic_long std::atomic<long>其中对于整形的特化而言,会有一些特殊的成员函数,例如:
- 原子加fetch_add;
- 原子减fetch_sub;
- 原子与fetch_and;
- 原子或fetch_or等。
常见操作符++、--、+=、&= 等也有对应的重载版本。
下面介绍最简单的atomic类型std::atomic_flag。
std::atomic_flag
这个类型的对象可以在两个状态间切换:设置和清除。
std::atomic_flag类型的对象必须被ATOMIC_FLAG_INIT初始化。
注意:初始化标志位总是“清除”状态。这里没得选择。
std::atomic_flag f = ATOMIC_FLAG_INIT;当你的标志对象已初始化,那么你只能做三件事情:销毁,清除或设置(查询之前的值)。
这些事情对应的函数分别是:
- clear()成员函数;
- test_and_set()成员函数;
std::atomic_flag非常适合于作自旋互斥锁。初始化标志是“清除”,并且互斥量处于解锁状态。为了锁上互斥量,循环运行test_and_set()直到旧值为false,就意味着这个线程已经被设置为true了。解锁互斥量是一件很简单的事情,将标志清除即可。如下所示:
class spinlock_mutex
{
std::atomic_flag flag;
public:
spinlock_mutex():
flag(ATOMIC_FLAG_INIT)
{}
void lock()
{
while(flag.test_and_set(std::memory_order_acquire));
}
void unlock()
{
flag.clear(std::memory_order_release);
}
};究竟是有锁还是无锁
想要达到atomic的效果,我们可以用无锁实现(原子操作)or 有锁实现(如mutex)来达到。
C++11的atomic<>会根据设备硬件来选择是无锁实现还是有锁实现。也就是说同一类型在不同硬件上的表现可能不同。
知道某type是否支持无锁atomic这一点很重要。先抛出结论:
atomic_flag无论在何种机器上,都是保证无锁的;
注意atomic<bool>和atomic_flag表现很像,但前者不保证是无锁的。尽管大多数情况下,前者是无锁实现的,但c++不提供强保证。atomic<T>,若T的大小是1、2、4、8个字节时,大部分情况是无锁实现的;
补充,有些平台实现了对双字长的类型的原子操作,这些平台通常支持所谓的“双字节比较和交换”double-word-compare-and-swap。- 对于自建类型而言,前提是TriviallyCopyable类型,且是“位可比的”才能通过无锁实现;
TriviallyCopyable类型等价于支持memcpy(),位可比的等价于支持memcpy()。
为了支持memcpy,该自建类型的拷贝赋值函数是编译器自动生成的,也就是说不允许有用户自己编写的烤白赋值函数代码。
这两个要求,是为了保证CAS操作能够正常工作。
所以,对于复杂的自建类型,如std::atomic<std::vector<int>>自然是不合适用atomic来实现并发的,更适合用mutex有锁。
此外,显然自建类型中不应该出现指针、引用。
C++标准为每个atomic类型提供了is_lock_free(),我们可以通过该成员函数,判断在此机器下,该类型是无锁还是有锁。
比如:
#define N 8
struct A {
char a[N];
};
int main()
{
std::atomic<A> a;
std::cout << a.is_lock_free() << std::endl;
return 0;
}最后总结一下,各个atomic支持的operator:
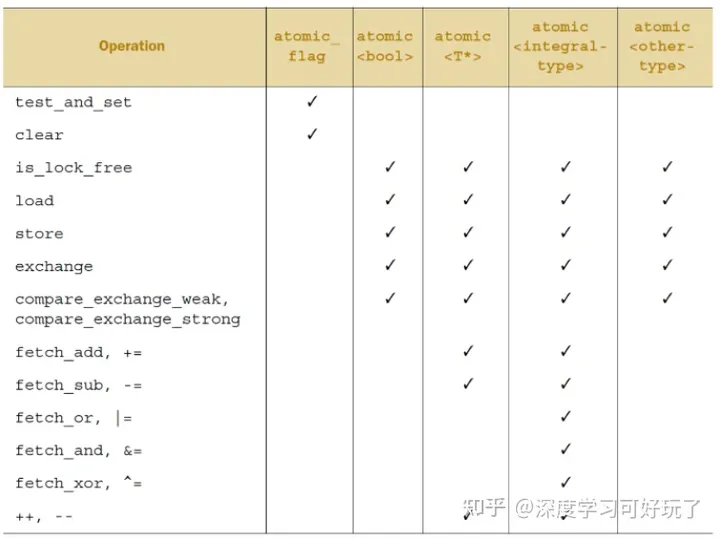
C++原子类型的CAS成员函数
compare_exchange_weak(expect,desired)和compare_exchange_strong(expect,desired)是C++原子类型的CAS成员函数。
- 当前值与期望值(expect)相等时,修改当前值为设定值(desired),返回true;
- 当前值与期望值(expect)不等时,将期望值(expect)修改为当前值,返回false;
- 返回值是一个bool;
weak版和strong版的区别: weak版本的CAS允许偶然出乎意料的返回(比如在字段值和期待值一样的时候却返回了false),不过在一些循环算法中,这是可以接受的。通常它比起strong有更高的性能,所以一般都采用weak。
下面举个例子,参考自文章,用无锁实现的顺序数组的入栈:
auto max_val = getMaxValue(); // 获取值上界
auto now_val = getValue(); // 获取当前值
auto exp_val = now_val; // 期望值为当前值
do {
if(exp_val == max_val) break; // 到达上界退出循环
} while(!now_val.compare_exchange_weak(exp_val, exp_val + 1)) // 失败的话会更新expect为当前值
// 从第2行到第5行代码可能被其他线程中断改变now_val的值思考一个问题:为什么这里不能用原子加1替代呢?
其实这里还有一个用处,也就是对期望值(或当前值)进行判断,比如当到达一个临界值以后就停止累加,原子加法没法将加1之后的判断也绑定到同一个原子操作中,也就没法实现这一点。而CAS的循环体中则可以实现一个 “准改判断”——不满足条件就不允许修改当前值。
C++六种内存顺序
指令重排问题
有时候,我们会用一个变量作为标志位,当这个变量等于某个特定值的时候就进行某些操作。但是这样依然可能会有一些意想不到的坑,例如两个线程以如下顺序执行:
| step | thread A | thread B |
|---|---|---|
| 1 | a = 1 | |
| 2 | flag= true | |
| 3 | if flag== true | |
| 4 | assert(a == 1) |
当B判断flag为true后,断言a为1,看起来的确是这样。那么一定是这样吗?可能不是,因为编译器和CPU都可能将指令进行重排。实际上的执行顺序可能变成这样:
| step | thread A | thread B |
|---|---|---|
| 1 | flag = true | |
| 2 | if flag== true | |
| 3 | assert(a == 1) | |
| 4 | a = 1 |
这就导致了step3的时候断言失败。
为什么编译器和CPU在执行时会对指令进行重排呢?
因为现代CPU采用多发射技术(同时有多条指令并行)、流水线技术,为了避免流水线断流,CPU会进行适当的指令重排。这在计算机组成原理的流水线一节有所涉及,如果是单线程任务,那么一切正常,CPU和编译器对代码顺序调换是符合程序逻辑的,不会出错。但一到多线程编程中,结果就可能如上例所示。
C++11引入了非常重要的内存顺序概念,用以解决上述指令重排问题。
实际上,之前介绍的atomic类型的成员函数有一个额外参数,以store为例:
void store( T desired, std::memory_order order = std::memory_order_seq_cst )这个参数代表了该操作使用的内存顺序,用于控制变量在不同线程见的顺序可见性问题,不只store,其他成员函数也带有该参数。
c++11提供了六种内存顺序供选择:
typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
} memory_order;之前在场景2中,因为指令的重排导致了意料之外的错误,通过使用原子变量并选择合适内存序,可以解决这个问题。下面先来看看这几种内存序
memory_order_release/memory_order_acquire
memory_order_release用于store成员函数。
在本行代码之前,如果有任何写内存的操作,都是不能放到本行语句之后的。
简单地说,就是写不后。即,写语句不能调到本条语句之后。memory_order_acquire用于load成员函数
就是读不前
举个例子:
假设flag为一个 atomic特化的bool 原子量,a为一个int变量,并且有如下时序的操作:
| step | thread A | thread B |
|---|---|---|
| 1 | a = 1 | |
| 2 | flag.store(true, memory_order_release) | |
| 3 | if( true == flag.load(memory_order_acquire)) | |
| 4 | assert(a == 1) |
在这种情况下,step1不会跑到step2后面去,step4不会跑到step3前面去。
这样一来,保证了当读取到flag为true的时候a一定已经被写入为1了。
换一种比较严谨的描述方式可以总结为:对于同一个原子量,release操作前的写入,一定对随后acquire操作后的读取可见。 这两种内存序是需要配对使用的,这也是将他们放在一起介绍的原因。
还有一点需要注意的是:只有对同一个原子量进行操作才会有上面的保证,比如step3如果是读取了另一个原子量flag2,是不能保证读取到a的值为1的。
memory_order_release/memory_order_consume
memory_order_release还可以和memory_order_consume搭配使用。
- memory_order_release的作用跟上面介绍的一样。
- memory_order_consume用于load操作。
这个组合比上一种更宽松,comsume只阻止对这个原子量有依赖的操作重排到前面去,而非像aquire一样全部阻止。
comsume操作防止在其后对原子变量有依赖的操作被重排到前面去,对无依赖的操作不做限定。这种情况下:对于同一个原子变量,release操作所依赖的写入,一定对随后consume操作后依赖于该原子变量的操作可见。
将上面的例子稍加改造来展示这种内存序,假设flag为一个 atomic特化的bool 原子量,a为一个int变量,b、c各为一个bool变量,并且有如下时序的操作:
| step | thread A | thread B |
|---|---|---|
| 1 | b = true | |
| 2 | a = 1 | |
| 3 | flag.store(b, memory_order_release) | |
| 4 | while (!(c = flag.load(memory_order_consume))) | |
| 5 | assert(a == 1) | |
| 6 | assert(c == true) | |
| 7 | assert(b == true) |
step4使得c依赖于flag,所以step6断言成功。
由于flag依赖于b,b在之前的写入是可见的,此时b一定为true,所以step7的断言一定会成功。而且这种依赖关系具有传递性,假如b又依赖与另一个变量d,则d在之前的写入同样对step4之后的操作可见。
那么a呢?很遗憾在这种内存序下a并不能得到保证,step5的断言可能会失败。
memory_order_acq_rel
这个选项看名字就很像release和acquire的结合体,实际上它的确兼具两者的特性。
这个操作用于“读取-修改-写回”这一类既有读取又有修改的操作,例如CAS操作。可以将这个操作在内存序中的作用想象为将release操作和acquire操作捆在一起,因此任何读写操作的重排都不能跨越这个调用。
依然以一个例子来说明,flag为一个 atomic特化的bool 原子量,a、c各为一个int变量,b为一个bool变量:
| step | thread A | thread B |
|---|---|---|
| 1 | a = 1 | |
| 2 | flag.store(true, memory_order_release) | |
| 3 | b = true | |
| 4 | c = 2 | |
| 5 | while (!flag.compare_exchange_weak(b, false, memory_order_acq_rel)) {b = true} | |
| 6 | assert(a == 1) | |
| 7 | if (true == flag.load(memory_order_acquire) | |
| 8 | assert(c == 2) |
由于memory_order_acq_rel同时具有memory_order_release与memory_order_acquire的作用,因此step2可以和step5组合成上面提到的release/acquire组合,因此step6的断言一定会成功,而step5又可以和step7组成release/acquire组合,step8的断言同样一定会成功。
memory_order_seq_cst
该内存顺序是各个成员函数的内存顺序的默认选项。
它是最严格的内存顺序,一句话说就是:在这条语句的时候 所有这条指令前面的语句不能放到后面,所有这条语句后面的语句不能放到前面来执行。
memory_order_relaxed
这个选项如同其名字——自由。它仅仅只保证其成员函数操作本身是原子不可分割的,但是对于顺序性不做任何保证。
顺序一致性和cache一致性区别
memory_order_seq_cst和memory_order_acq_rel的区别
参考文档
https://www.codedump.info/post/20191214-cxx11-memory-model-1/
https://www.codedump.info/post/20191214-cxx11-memory-model-2/
https://github.com/apache/brpc/blob/master/docs/cn/atomic_instructions.md