
一、正排
当在投广告的总数较少(几百~几千)时,最简单的做法是遍历。但是如果广告数目太多,则时间复杂度太高O(n*m)
def ad_targeting(request, ads):
candidates = []
for ad in ads:
match = True
for field, value in request.tags:
if !ads.match(field, value):
match = False
break
if match:
candidates.append(ad)
return candidates二、倒排
构建倒排索引:
field_names = ["city", "gender", "age"]
def build_inverted_index(ads):
index = {} # field -> value -> array_of_ads
for ad in ads:
index["all"][NOT_SPECIFIED].add(ad)
for field in field_names:
value = ad.get_targeting_value(field)
if value is None:
index[field][NOT_SPECIFIED].add(ad)
else:
index[field][value].add(ad) # set.add
return index需要注意的细节:value 为 None 的情况,代表广告未设置该定向条件(例如不限性别),需要将该广告加入一个特定的集合里(value = NOT_SPECIFIED)。
然后在收到流量请求时,将每个定向条件的倒排集合求交,即可得到所有可投的广告:
def ad_targeting(request, index):
ads = None
for field in field_name:
value = request.tags.get(field)
if value is None:
# 流量缺失该标签,只能投放未定向该标签的广告
field_ads = index["field"][NOT_SPECIFIED]
else:
# 可投放 [未定向该字段] 或 [定向该字段=某值]的广告
field_ads = copy(index["field"][NOT_SPECIFIED])
field_ads.union(index["field"][value])
if ads is None:
ads = field_ads
else:
ads.intersect(field_ads)
return ads具体实现还可以有一些改进点:
1.在同一个定向条件下可以选择多个取值,例如希望投放一线城市,那么就应该是 city in [北、上、广、深];
2.定向条件可能还需要支持取反,例如 city not in [北、上、广、深],可以用集合求差集来实现;
3.对于年龄等取值较多的字段,可以采用划分年龄段的方式减少倒排的枚举值。
三、bitmap
bitmap结构一般作为倒排key value中的value,代表的是当前key条件下的广告集合。
通过引入 bitmap ,我们可以大幅提高集合操作(交、并、差)的运算效率:由于数据是连续存储且位运算不需要比较操作,因此能显著提高 cache 命中率(包括数据 cache 和指令 cache )。
1.普通的bitmap
算法原理
当数据表中某个字段下取值范围较少时,比如对于性别,可取值的范围只有{‘男’,’女’},并且男和女可能各占该表的50%的数据,这时添加B树索引还是需要取出一半的数据查询。
如果用户查询的列的基数非常的小, 即只有的几个固定值,如性别、婚姻状况、行政区等等。要为这些基数值比较小的列建索引,就需要建立位图索引。
对于性别这个列,位图索引形成两个向量,男向量为10100…,(向量长度为N),向量的每一位表示该行是否是男,如果是则位1,否为0,同理,女向量位01011…。
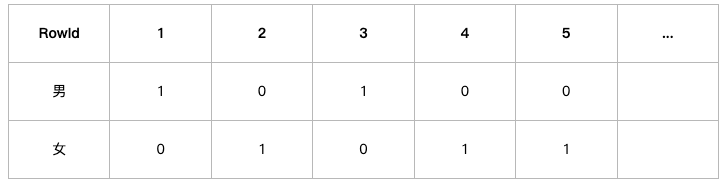
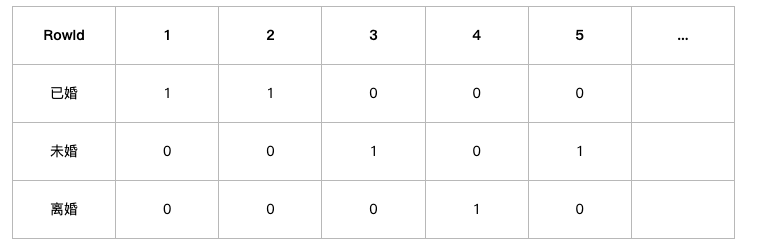
对于婚姻状况这一列,位图索引生成三个向量,已婚为11000…,未婚为00100…,离婚为00010…。
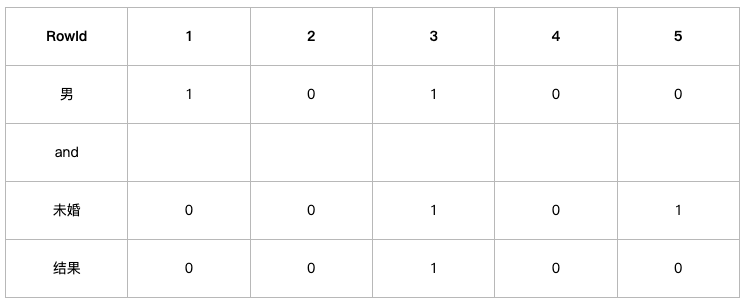
当我们使用查询语句“select * from table where Gender=‘男’ and Marital=“未婚”;”的时候 首先取出男向量10100…,然后取出未婚向量00100…,将两个向量做and操作,这时生成新向量00100…,可以发现第三位为1,表示该表的第三行数据就是我们需要查询的结果。
位图索引的适用条件
位图索引适合只有几个固定值的列,如性别、婚姻状况、行政区等等,而身份证号这种类型不适合用位图索引
此外,位图索引适合静态数据,而不适合索引频繁更新的列。举个例子,有这样一个字段busy,记录各个机器的繁忙与否,当机器忙碌时,busy为1,当机器不忙碌时,busy为0。
参考:https://www.cnblogs.com/lbser/p/3322630.html
2.压缩的bitmap(Roaring Bitmaps)
Bitmap 比较适用于数据分布比较稠密的存储场景中,对于原始的 Bitmap 来说,若要存储一个 uint32 类型数据(在广告的场景中就是指广告数量有2^32个),这就需要 2 ^ 32 长度的 bit 数组,通过计算可以发现(2 ^ 32 / 8 bytes = 512MB),一个普通的 Bitmap 需要耗费 512MB 的存储空间。如果我们只存储几个数据的话依然需要占用 512M 的话,就有些浪费空间了,因此我们可以采用对位图进行压缩的 RoaingBitmap,以此减少内存和提高效率。
算法原理
虽然位图索引可以显著加快查询速度,但是,位图索引会占用大量的内存,因此我们会更喜欢压缩位图索引。
RBM 的主要思想并不复杂,简单来讲,有如下三条:
我们将 32-bit 的范围 ([0, n)) 划分为 2^16 个桶,每一个桶有一个 Container 来存放一个数值的低16位;
在存储和查询数值的时候,我们将一个数值 k 划分为高 16 位(k % 2^16)和低 16 位(k mod 2^16),取高 16 位找到对应的桶,然后在低 16 位存放在相应的 Container 中;
容器的话, RBM 使用两种容器结构: Array Container 和 Bitmap Container。Array Container 存放稀疏的数据,Bitmap Container 存放稠密的数据。即,若一个 Container 里面的 Integer 数量小于 4096,就用 Short 类型的有序数组来存储值。若大于 4096,就用 Bitmap 来存储值。
举例说明
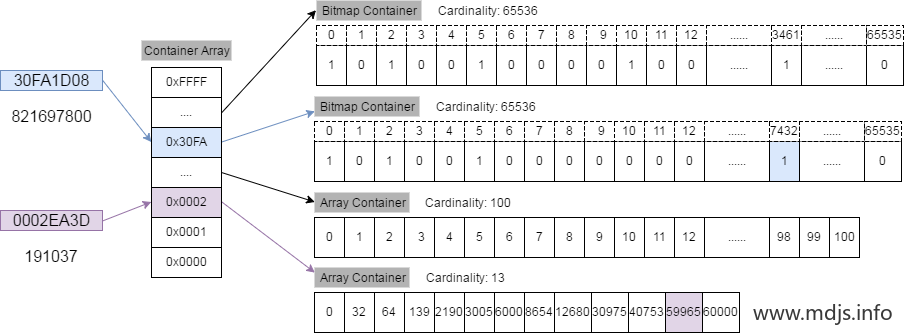
现在我们要将 821697800 这个 32 bit 的整数插入 RBM 中,整个算法流程是这样的:
821697800 对应的 16 进制数为 30FA1D08, 其中高 16 位为 30FA, 低16位为 1D08。
我们先用二分查找从一级索引(即 Container Array)中找到数值为 30FA 的容器(如果该容器不存在,则新建一个),从图中我们可以看到,该容器是一个 Bitmap 容器。
找到了相应的容器后,看一下低 16 位的数值 1D08,它相当于是 7432,因此在 Bitmap 中找到相应的位置,将其置为 1 即可。
原理补充
RBM 的基本原理就这些,基于这种设计原理会有一些额外的操作要提一下。
请注意上文提到的一句话:
若一个 Container 里面的 Integer 数量小于 4096,就用 Short 类型的有序数组来存储值。若大于 4096,就用 Bitmap 来存储值。
先解释一下为什么这里用的 4096 这个阈值?因为一个 Integer 的低 16 位是 2Byte,因此对应到 Arrary Container 中的话就是 2Byte * 4096 = 8KB;同样,对于 Bitmap Container 来讲,2^16 个 bit 也相当于是 8KB。
然后,基于前面提到的两种 Container,在两个 Container 之间的 Union (bitwise OR) 或者 Intersection (bitwise AND) 操作又会出现下面三种场景:
Bitmap vs Bitmap
Bitmap vs Array
Array vs Array
参考:
https://www.modb.pro/db/218968
(bitmap的缺点是反定向不太好做)
四、布尔索引
我们定义如下术语:
1.Attribute:单个流量标签,包含两个信息:属性类别和属性取值。如:AGE: 5
2.Assignment:多个流量标签组成的用户画像。如:AGE: 5,GENDER: 1,NETWORK: 1
3.Conjunction:布尔表达式的合取范式。如:AGE ∈ (4,5,6) ∧ GENDER ∈ (1)
两层索引设计的主要思想是:从Assignment 找出包含这些流量标签的Conjunction,筛选满足条件的Conjunction,根据筛选出的Conjunction,找出满足条件的广告集合。下面我们举个例子:
假设线上有7个广告,它们定向条件如下,其中A3和Ad7定向条件相同。Ad6包含反向定向,即该广告不能出在AppInterest的标签为(19-1)的用户上面。
Ad1定向:PlacementType∈(2)
Ad2定向:PlacementType∈(2) ∧ AppInterest∈(15-0, 19-1) ∧ InstalledApp∈(30202)
Ad3定向:PlacementType∈(2) ∧ AppInterest∈(15-0, 19-1) ∧ NetworkType∈(1)
Ad4定向:PlacementType∈(2) ∧ AppInterest∈(19-1)
Ad5定向:PlacementType∈(2) ∧ InstalledApp∈(30202) ∧ NetworkType∈(1)
Ad6定向:PlacementType∈(2) ∧ IpGeo∈(141) ∧ NetworkType∈(1) ∧ AppInterest∉(19-1)
Ad7定向:PlacementType∈(2) ∧ AppInterest∈(15-0, 19-1) ∧ NetworkType∈(1)对应定向条件有6个Conjuntion,可编号Conjuntion如下:
| conjunctionId | conjunction | size |
|---|---|---|
| 1 | PlacementType∈(2) | 1 |
| 2 | PlacementType∈(2) ∧ AppInterest∈(19-1) | 2 |
| 3 | PlacementType∈(2) ∧ IpGeo∈(141) ∧ NetworkType∈(1) ∧ AppInterest∉(19-1) | 3 |
| 4 | PlacementType∈(2) ∧ InstalledApp∈(30202) ∧ NetworkType∈(1) | 3 |
| 5 | PlacementType∈(2) ∧ AppInterest∈(15-0, 19-1) ∧ InstalledApp∈(30202) | 3 |
| 6 | PlacementType∈(2) ∧ AppInterest∈(15-0, 19-1) ∧ NetworkType∈(1) | 3 |
其中,conjunctionId为编号,conjunction为布尔表达式内容,size为∈语句的个数。
可以建立conjunctionId到Ad的索引如下:
conjunction1 -> Ad1
conjunction2 -> Ad4
conjunction3 -> Ad6
conjunction4 -> Ad5
conjunction5 -> Ad2
conjunction6 -> Ad3,Ad7流量标签到布尔表达式的索引如下:
| K | Attribute(Key) | PostingList(conjunctionId,代表包含/不包含) |
|---|---|---|
| 1 | PlacementType:2 | (1, ∈) |
| 2 | PlacementType:2 | (2, ∈) |
| AppInterest: 19-1 | (2, ∈) | |
| 3 | PlacementType:2 | (3, ∈), (4, ∈), (5, ∈), (6, ∈) |
| AppInterest:19-1 | (3, ∉), (5, ∈), (6, ∈) | |
| AppInterest:15-0 | (5, ∈), (6, ∈) | |
| InstalledApp:30202 | (4 ∈), (5, ∈) | |
| NetworkType: 1 | (3, ∈), (4, ∈), (6, ∈) | |
| IpGeo:141 | (3, ∈) |
如上图,建立K-Index
K 代表Conjuntion的size大小
PostingList代表包含/不包含这个Attribute的Conjuntion
算法原理
我们还是按照上面的例子说明,最后给出核心算法的伪代码。现在来了一个用户画像Assignment:
PlacementType:2
AppInterest:19-1
NetworkType:1由于有三个流量标签,那么我们满足条件的只可能是1-Index, 2-Index,3-Index。这就是为什么上面建索引的时候需要建立一个K-Index的索引,加上K-Index可以根据数目进行算法剪枝。同时每一个PostingList中的Conjuntion都已按照ConjuntionId升序排列。我们以检测3-Index为例。根据Assignment可以从索引里面取到如Conjuntions:
PlacementType: 2 (3, ∈), (4, ∈), (5, ∈), (6, ∈)
AppInterest: 19-1 (3, ∉), (5, ∈), (6, ∈)
NetworkType: 1 (3, ∈), (4, ∈), (6, ∈)需要判断当前最小的ConjuntionId至少出现在3个PostingList中,且不能出现∉的关系。
每次check完成之后按照conjuntionId重排序(方便检测是不是至少出现在3个PostingList中)。
PlacementType: 2 (3, ∈), (4, ∈), (5, ∈), (6, ∈)
AppInterest: 19-1 (3, ∉), (5, ∈), (6, ∈)
NetworkType: 1 (3, ∈), (4, ∈), (6, ∈)
\-------------------------------------------------------
MatchedConjuntion = []
(check Conjuntion3,发现出现了∉,故不满足)
PlacementType: 2 (4, ∈), (5, ∈), (6, ∈)
NetworkType: 1 (4, ∈), (6, ∈)
AppInterest: 19-1 (5, ∈), (6, ∈)
\-------------------------------------------------------
MatchedConjuntion = []
(check Conjuntion4,发现出现只出现在两个中,故不满足)
PlacementType: 2 (5, ∈), (6, ∈)
AppInterest: 19-1 (5, ∈), (6, ∈)
NetworkType: 1 (6, ∈)
\-------------------------------------------------------
MatchedConjuntion = []
(check Conjuntion5,发现出现只出现在两个中,故不满足)
PlacementType: 2 (6, ∈)
AppInterest: 19-1 (6, ∈)
NetworkType: 1 (6, ∈)
\-------------------------------------------------------
MatchedConjuntion = []
(check Conjuntion6,至少出现在三个中,且没有∉关系,满足)按照该算法继续检测2-Index、1-Index。得到最终结果: MatchedConjuntion =[1,2,6]。再根据MatchedConjuntion 检索出广告 MatchedAds = [Ad1, Ad4, Ad3,Ad7]。
维度爆炸问题
有的同学觉得这里会出现维度爆炸的问题,比如有50个兴趣标签,5个年龄段标签,2个性格标签。最极端的情况是可能会出现:
50 * 5 * 2 * ... = 100 * ...随着定向维度的增加而爆炸,实际上并不会,因为定向维度是取决于广告的规模的,最极端情况,假设我们线上有100w的广告,且这100w的广告定向标签都不一样,那么问题规模也是100w,并不会出现维度爆炸。另外,实际上,线上大量广告的定向标签是重复的,100w的广告定向的Conjuntion,远远小于广告数量。
用ES可以做吗?
es检索的dsl条件的伪代码如下:
[(不存在性别定向)|| (存在性别定向且满足条件)]
&& [(不存在年龄定向)|| (存在年龄定向且满足条件)]
&& [(不存在标签定向)|| (存在标签定向且满足条件)]
...这样就可以把通投的(无任何定向)广告和有定向且满足条件的广告检索出来。
例如:请求是:26岁的男性用户,那么实际的es的dsl为:
{
"must": [
{
"bool": {
"should": [
{
"bool": {
"must_not": {
"exists": {
"field": "age"
}
}
}
},
{
"bool": {
"should": [
{
"range": {
"age.min": {
"from": null,
"to": 26,
"include_lower": true,
"include_upper": true
}
}
},
{
"range": {
"age.max": {
"from": 26,
"to": null,
"include_lower": true,
"include_upper": true
}
}
}
]
}
}
]
}
},
{
"bool": {
"should": [
{
"bool": {
"must_not": {
"exists": {
"field": "gender"
}
}
}
},
{
"term": {
"gender": "男"
}
}
]
}
}
]
}